
【导读】在当今软件开发和科学研究领域,项目的复杂性日益增加,提升研发效率已成为行业迫切需求。本文深入探讨了大模型技术在研发效率提升方面的应用与实践,以实战摸索的方式,真实揭示了大模型究竟能够如何助力企业实现数智化转型。
本文精选自《新程序员007:大模型时代的开发者》,《新程序员 007》聚焦开发者成长,其间既有图灵奖得主 Joseph Sifakis、前 OpenAI科学家 Joel Lehman 等远瞩,又有对于开发者们至关重要的成长路径、工程实践及趟坑经验等,欢迎大家点击订阅年卡。
随着软件开发和科学研究的复杂性不断增加,人们对提高编程及研发效率的需求也越来越迫切。传统的编程工具和方法已经无法满足这一需求,因此人们开始探索新的技术手段来提升编程和研发效率。大模型作为一种新兴的人工智能技术,被广泛应用于辅助编程和研发效率提升领域。
例如,美国科技巨头谷歌利用大模型技术提升内部研发效率,通过在代码自增长工具中集成大模型,辅助完成部分重复性工作(如自动导入包、自动生成构造函数等),缩短了工程师的编码时间。同时它还开源了基于大模型的代码搜索引擎,可以自动匹配代码片段并提供相关文档,大幅提高了工程师的开发效率。微软研究院则开发了基于大模型的自动测试工具,它可以自动检测代码中的 Bug,并生成相应的测试用例。经过实测,该工具在发现错误率和测试覆盖率上都能超越人工编写的测试用例。目前它正在帮助微软各产品线提升测试质量。
中兴通讯以大模型为中心赋能企业数智化转型,坚持先自用再外溢。除自研大模型之外,我们还基于开源的大模型开发微调后在研发效能领域进行应用,并分析其优势和挑战。通过对相关研究和实践案例的综述,发现大模型在辅助编程和研发效率提升方面具有巨大潜力。在本文中,我将分享我们在研发类大模型的一些应用与实践,希望对开发者们有所裨益。
研发流程非常繁多,从项目立项到需求分析,再到产品设计、研发,再进行测试,进而投产和运维,贯穿了复杂的管理流程。
大模型能对用户提出的需求进行语义理解,识别其内在结构与逻辑关系,自动将需求拆分成独立的子需求。比如从一个用户定义的需求,自动提取出多个具体的产品需求点。
(1)根据用户自然语言自动创建符合用户需求的流水线)根据代码库结构,结合部门代码库和流水线规范,自动生成流水线)通过 A
此外,开发流水线)在不同阶段进行分支管理与合并。(2)监控流水线状态并发送实时提醒,追踪任务进度。
测试用例代码生成,即不同粒度的自动化测试用例代码生成,包括函数级、模块级、功能级、API 级、性能级。
自动创建测试环境,即自动创建测试环境、测试执行任务并执行,最后生成测试报告。自动生成测试文档,包括:
这是目前综合性能与部署成本的平衡点。像 10B 左右的微型模型,在保留很强生成能力的同时,参数量相对较小,易于部署和精调。
如果有一定预算,可以选择略大一些的模型,像 GPT-J 25B,具有更全面强大的语言理解和应用能力。若重视研发投入且需要应对更复杂任务,选择 50B 以下大模型也未尝不可。
超过 100B 的天然语言处理大模型,由于其部署和使用成本还不可控,当前尚不宜直接应用于产品。
总体而言,当前 10B - 50B 之间的模型规模是一个比较适宜的选择窗口。它可以满足大多数日常需求,同时考虑到成本和易用性的因素,超过这个范围就需要根据实际应用场景具体权衡。其次,还需要考虑模型的开源程度。半开源模型
具备编程领域能力,在编程类模型评估中各类语言得分越高越好(HumanEval/Babelcode 指标)。考虑模型参数量,参数量过大,会导致精调和部署成本的提升。

模型选好后,接下来就是对模型进行增强预训练。增强预训练的框架要解决两个问题:资源和速度。我们采用以下优化方式:
对于模型训练,我们可以采用 3D 并行训练的方式来实现。将模型参数和梯度张量划分为多个分区,分配到不同GPU卡上进行计算。每张卡负责自己分区的梯度和参数更新工作,间隔时同步到其他卡上。这样可以很好地利用更多计算资源,降低单卡资源需求。
d Data Parallel 的方式,将训练数据并行读取和样本处理工作分发到各节点,充分利用多卡资源进一步提升训练速度。对于节省 GPU 资源,我们使用 ZeRO 技术。这个技术通过对静态和动态参数/张量进行精细地分区存储,有效减少显存占用。同时它支持异步参数更新,计算和参数传输可以重叠进行,有效缩短迭代周期。对于模型训练加速,我们采用 FlashAtten
on 技术。它通过对注意力操作进行分块并进行融合,如将 QK 乘积和后续运算融成一个算子,可以大幅减少数据传输次数,从而提升计算吞吐。
明确训练数据的来源、用途和特点。在组织训练数据前,要了解数据的来源,确认其可靠性和有效性。同时,要明确这些数据将用于哪些任务,并了解其特点,如数据量的大小、数据类型等。
进行数据预处理。预处理是组织训练数据的关键步骤,包括数据清理、去重、变换等。数据清理主要是去除无效、错误或重复的数据;去重则是去除重复的信息,以避免模型过拟合;变换则是对数据进行必要的转换,以便于模型的学习和训练。合理组织训练数据。首先要将数据进行分类,按照不同的任务需求划分不同的数据集。例如,可以将数据集分为训练集、验证集和测试集,以便于模型的训练和测试。同时,要合理存储数据文件,可以选择常见的存储格式,如 CSV、JSON 等,并确保文件的安全性和完整性。
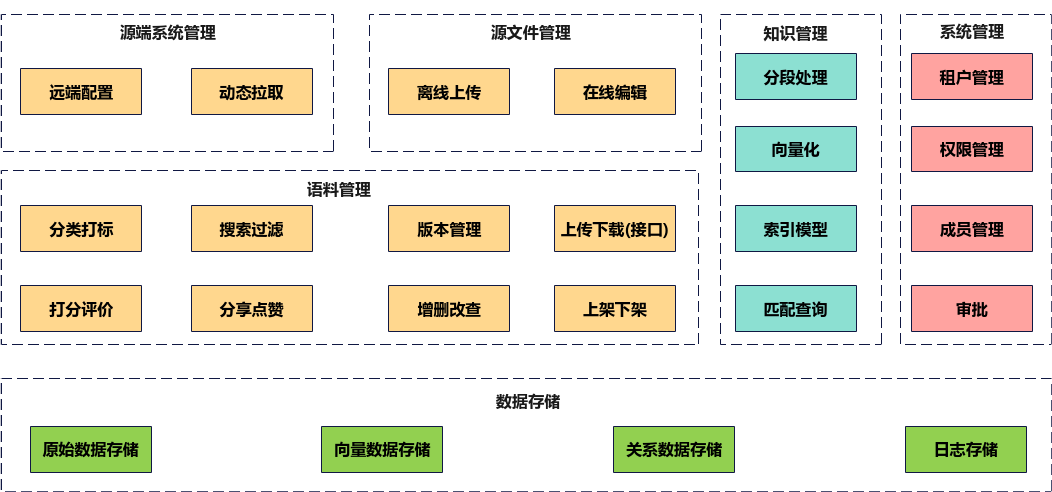
语料库是语言学研究的基础,为自然语言处理任务提供丰富的语料信息。建设语料库的目的是为了满足特定语言任务的需求,如文本分类、情感分析、信息提取等。
选择合适的语料库构建方法。常用的语料库构建方法有手工采集、自动化采集和混合采集。手工采集适用于小规模、高质量的语料库建设;自动化采集则可以快速地获取大量语料信息;混合采集则是结合前两种方法的优势,以获得高质量且大规模的语料库。做好语料库的管理和维护。为了确保语料库的安全性和可靠性,需要对语料库进行科学的管理和维护,这包括文件管理、关键词提取、数据备份等。要建立完善的文件管理制度,对语料库进行合理的分类和存储;同时,要定期对语料库进行关键词提取,以便于检索和使用;此外,还要定期备份语料库数据,以防止数据丢失或损坏。
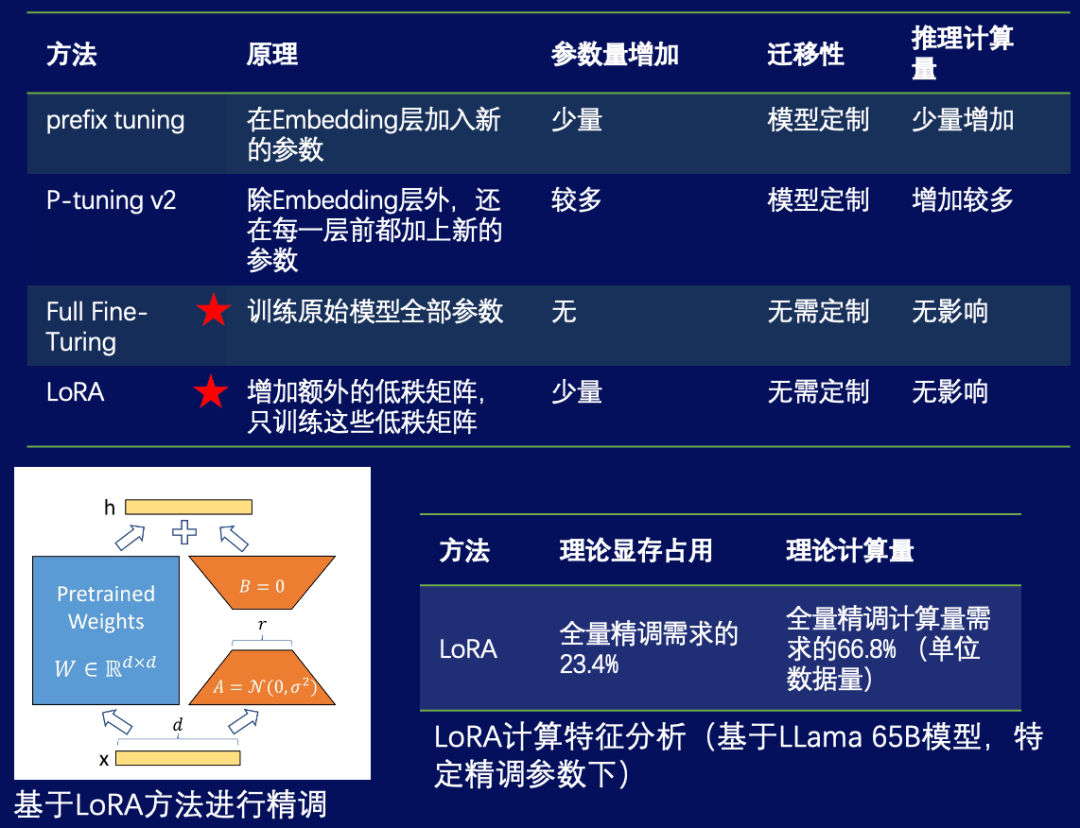
接下来,需要对大模型进行精调。针对已经预训练好的研发大模型,在具体应用任务上进行优化和微调,以适应研发领域和应用场景的需求。在精调中,面临的问题包括:
大模型通常需要大量的显存来存储模型参数和中间状态,而显存的有限性限制了模型的规模。在进行精调时,如果使用的数据量较大或者模型的复杂度较高,显存占用量可能会超过预训练的需求,导致模型训练失败或效率低下。
核心数、GPU 内存和显存等。在进行精调时,如果使用的数据量较大或者模型复杂度较高,计算量可能会超过预训练的需求(单位数据量),导致模型训练速度变慢或者无法收敛。此外,大模型精调还可能面临其他问题,如模型复杂度过高导致调参困难、数据量过大导致过拟合风险增加等。因此,在进行大模型精调时,需要根据实际情况进行权衡和优化。
内部上线在短短两个月的时间里就取得了显著的效果。用户超过 3000 人,30 日留存率超过 50%,产品成功完成冷启动。在这背后是仅使用了 4 张 A800 卡,这意味着 AI 编程成本完全可以被企业所接受。需要注意的是,AI 编程对人员能力有比较高的要求,需要对员工进行系统性培训,才可能用得更好。当然,大模型的使用也面临一些挑战,如计算资源需求和数据隐私问题。这些挑战主要来自于大模型庞大的计算规模和对大量个人敏感数据的依赖。经典的大模型需要大量 GPU 资源进行训练与推理,离线部署效率低下;同时由于学习自大量的互联网数据,模型内可能含有用户隐私信息。
因此,未来的研究应重点关注如何利用分布式计算和隐私保护技术等手段,来解决大模型计算资源和数据隐私的问题。例如采用 Model Parallel(模型并行)和 Data Parallel(数据并行)方法降低单机硬件需求,使用关注点机制和微分隐私等隐私算法来保护用户数据等。同时也应探索如何设计支持在线增量学习的大模型架构,有效应对业务需要持续迭代优化模型的需求。只有解决这些建设性的挑战,大模型才能在软件研发深度应用和持续推广。审核编辑:黄飞
和创新方法,看板方法如何助力阿里健康医药B2B业务发展,以及与敏捷教练一起互动交流如何将敏捷理念实施
产生的数据与信息见视频3。视频3 BHM数据展示5总结 两年前完成的本系列推送的第一期《桥梁安全监测及巡检养护系统的
泰克2004-2005年示波器新产品发布暨测量技术系列研讨会全面展开。中国,北京2005年1月2
摘要:“一个20瓦的LED灯成本要200元,一个普通白炽灯泡才卖多少钱?”中科慧宝总裁胡冰,一
作为专为人工智能开发和部署提供全流程支持的端到端平台,AIStation能够以强大的资源调度和管理能力助力客户加速AI大
的出现正在加速信息技术进入智能原生时代,并使得人机自然交互真正成为可能。而混合AI,端云协同等人工智能技术新的发展趋势,为大
的潞晨科技Colossal-AI系统,用户可实现在本地算力平台一键训练、微调、推理、部署大

 0731-84811617/0731-84811695
0731-84811617/0731-84811695 